Teil 2 der Serie zur Multi-Agent-Orchestrierung
In Teil 1 dieser Serie, haben wir dargelegt, dass Multi-Agent-Orchestrierung Integrationskomplexitäten verstärkt, statt sie zu lösen. Wenn Ihren Systemen die APIs, die Datenqualität und die Real-Time-Synchronisierung fehlen, die KI-Agenten benötigen, behebt das Hinzufügen weiterer Agenten diese Lücken nicht.
Nun dazu, wie „integration-ready“ in der Praxis tatsächlich aussieht.
Integrationsarbeit sollte als Voraussetzung für Agent-zu-Agent-Orchestrierung behandelt werden. Andernfalls kann ein KI-Deployment Probleme sichtbar machen, die schwer zu beheben sind (und die sich hätten vermeiden lassen). Galileo warnt zum Beispiel vor ausgefeilten Halluzinationen:
- Ein Contract-Review-Tool erstellt Zusammenfassungen mit Rechtsprechungszitaten, die nicht existieren
- Procurement-Bots erstellen detaillierte Anbieter-Verträge für Phantom-Lieferanten
- Telco-Ops-Agenten lösen Reaktionen auf nicht existente „kritische landesweite Ausfälle“ aus
Diese Ergebnisse zu vermeiden beginnt bei der Integrationsschicht.
4 Anforderungen an Multi-Agent-Orchestrierung
Diese wurden in Teil 1 eingeführt. Hier folgt mehr Detail dazu, wie jede Anforderung auf Umsetzungsebene aussieht.
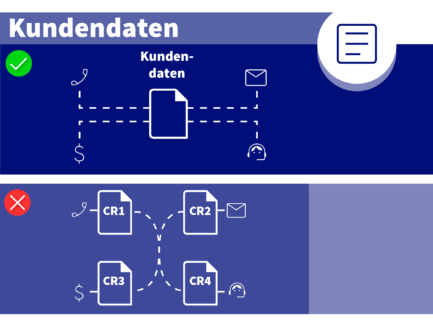
Vereinheitlichte Kundenidentität
Das bedeutet: ein einziger Kundendatensatz, der über Voice, Chat, CRM, Billing und Support-Historie hinweg erreichbar ist (kein Abgleich nach E-Mail in einem System, Telefonnummer in einem anderen und Account-ID in einem dritten).
KI-Agenten müssen „Wer ist dieser Kunde?“ auflösen, bevor sie koordinieren können: „Was braucht dieser Kunde?“. Wenn Ihre Systeme sich bei der Kundenidentität widersprechen, bricht Orchestrierung beim ersten Handoff.
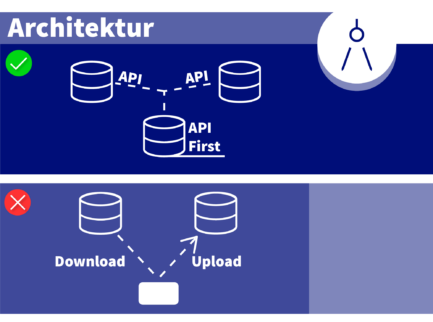
API-first-Architektur
Systeme müssen Daten über dokumentierte, versionierte APIs bereitstellen, die KI-Agenten programmgesteuert abfragen können. Screen Scraping, manuelle Exporte und Batch-Dateiübertragungen zählen nicht.
Das MCP, das KI-Agenten den Zugriff auf Enterprise-Systeme ermöglicht, benötigt programmgesteuerten Zugriff. Wenn Ihr Billing-System nur über eine Legacy-Terminaloberfläche abfragbar ist, hilft keine noch so starke Protokollstandardisierung.
Data Governance für den Zugriff von KI-Agenten
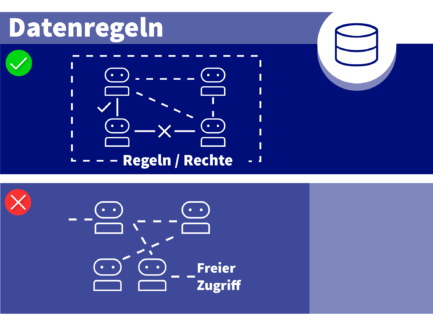
Das bedeutet: klare Richtlinien dazu, auf welche Daten KI-Agenten zugreifen dürfen, welche Aktionen sie ausführen können und was eine menschliche Freigabe erfordert. Es ist fast immer ein Fehler, KI-Agenten standardmässig dieselben Berechtigungen zu geben wie menschlichen Agenten.
Wenn mehrere Agenten koordinieren, müssen Sie wissen, welcher Agent welche Aktion autorisiert hat. Audit Trails werden essenziell. Ein einzelner KI-Agent, der eine fragwürdige Entscheidung trifft, ist nachvollziehbar. Mehrere Agenten, die Kontext ohne klare Governance weiterreichen, sind es nicht, und das Problem kann sich (schnell) verstärken.
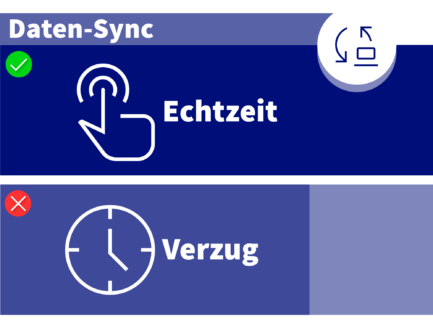
Real-Time-Datensynchronisierung
Änderungen in einem System müssen sich in anderen innerhalb von Sekunden widerspiegeln. Verzögerungen, nächtliche Batch-Jobs und manuelle Abgleichprozesse führen zu Drift.
Real-Time-Sync löst ein zentrales Problem: Wenn Ihr CRM einen anderen Saldo zeigt als Ihr Billing-System, welchem vertraut der Payment Agent? In Single-Agent-Automatisierung kann ein Mensch die Diskrepanz auflösen. In Multi-Agent-Orchestrierung propagiert sich diese Diskrepanz über jeden Agenten im Workflow.
Wo Integrationslücken sichtbar werden
Integrationslücken kündigen sich in der Planung nicht an. Sie zeigen sich beim Deployment, oft in vorhersagbaren Mustern.
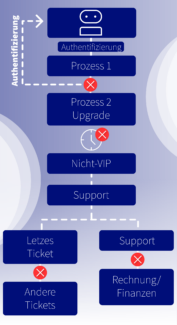
Authentication Handoff: Ein KI-Agent authentifiziert einen Kunden über Voice-Biometrie. Aber der Authentifizierungs-Kontext wird nicht an das nächste System im Workflow übergeben. Der Kunde muss sich erneut verifizieren. Vertrauen erodiert, bevor die Interaktion überhaupt beginnt.
Die Daten-Diskrepanz: Ein Kunde hat vor einer Stunde seinen Service-Plan upgegradet. Das Billing-System spiegelt es wider, aber das CRM des Support-Agenten zeigt noch den alten Tier. Der KI-Agent lehnt eine Feature-Anfrage ab, die der Kunde bereits bezahlt hat.
Die fehlende Historie: Ein KI-Agent kann auf das aktuelle Support-Ticket zugreifen, aber nicht auf die drei vorherigen Interaktionen, die erklären, warum der Kunde frustriert ist. Ohne diesen Kontext behandelt der Agent ein wiederkehrendes Problem wie ein neues. Der Kunde fühlt sich nicht gehört.
Die Permission Gap: Ein KI-Agent erkennt, dass eine Rückerstattung gerechtfertigt ist. Er kann die Transaktion sehen, die Diskrepanz verifizieren und die Lösung identifizieren. Aber er kann die Rückerstattung nicht ausführen, weil die Integration nicht mit Schreibzugriff gebaut wurde. Eskalation erforderlich. Das Automationsversprechen bricht.
Diese Muster haben einen gemeinsamen Nenner: Die Integration wurde für menschliche Workflows gebaut, nicht für KI-Agent-Workflows. Menschen können Lücken überbrücken. Sie können ein anderes System prüfen, eine klärende Frage stellen oder mit Kontext eskalieren. KI-Agenten, die autonom arbeiten, brauchen vollständige Integration.
Eine praktische Standortbestimmung
Wo steht Ihr Contact Center? Ein kurzer Diagnose-Check:
Basis fehlt
- Kundenidentität ist über Systeme fragmentiert
- Wichtige Systeme haben keinen API-Zugriff
- Es gibt keine formale Data Governance für den Zugriff von KI-Agenten
- Datensynchronisierung ist batch-basiert oder manuell
Implikation: Single-Agent-Automatisierung wird beim Datenzugriff kämpfen. Multi-Agent-Orchestrierung ist nicht praktikabel, bis diese Grundlagen adressiert sind. Starten Sie hier.
Basis teilweise vorhanden
- Kundenidentität ist in einigen Kanälen vereinheitlicht, aber nicht in allen
- Einige Systeme sind per API zugänglich; andere erfordern Workarounds
- Data Governance existiert, wurde aber nicht mit KI-Agenten im Blick entworfen
- Real-time-Sync funktioniert für manche Daten, für andere Batch
Implikation: Single-Agent-Automatisierung ist für eingegrenzte Use Cases möglich. Integrationslücken werden schnell sichtbar und müssen adressiert werden, bevor der Scope erweitert wird.
Basis stark
- Vereinheitlichte Kundenidentität existiert über alle Kanäle
- Kernsysteme folgen einer API-first-Architektur
- Data-Governance-Richtlinien berücksichtigen Zugriff und Auditierbarkeit für KI-Agenten
- Real-time-Synchronisierung ist systemübergreifend etabliert
Implikation: Bereit, Single-Agent-Automatisierung zu skalieren und Orchestrierung vorzubereiten. Der Fokus verschiebt sich auf Trust-Building, Analytics Instrumentation und Monitoring von A2A/MCP-Entwicklungen.
Die meisten Contact Center fallen in die Kategorie „Basis teilweise vorhanden“. Oft wurde bereits Integrationsarbeit für frühere Initiativen erledigt, etwa Omnichannel-Deployment oder CRM-Konsolidierungen. Aber Lücken bleiben, und diese Lücken werden sichtbar, sobald KI-Agenten operativ werden.

Die Integrations-Roadmap
Für Organisationen, die ihre Integrationsbasis noch aufbauen, folgt eine praktikable Sequenz. Zeitspannen sind richtungsweisend und variieren je nach Ausgangslage und Komplexität.
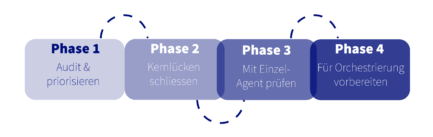
Phase 1: Audit und Priorisieren
Verschaffen Sie sich ein klares Bild davon, was existiert, was fehlt und was für Ihr initiales KI-Deployment am wichtigsten ist, zum Beispiel:
- Mapping, auf welche Systeme KI-Agenten für Ziel-Use Cases zugreifen müssen
- Identifizieren, welche Systeme API-Zugriff haben und welche nicht
- Dokumentieren, wie Kundenidentität systemübergreifend aufgelöst wird
- Data-Governance-Lücken markieren
Phase 2: Kritische Lücken schliessen
Nicht alles muss auf einmal gelöst werden. Priorisieren Sie entlang Ihrer Ziel-Use Cases, zum Beispiel:
- APIs für Systeme bauen oder verfügbar machen, denen sie fehlen
- Bewerten, ob Middleware oder Ersatz sinnvoll ist
- Eine Layerzur Auflösung der Kundenidentität implementieren, falls sie fehlt
- Data-Governance-Richtlinien für den Zugriff von KI-Agenten etablieren
- Real-time-Sync-Anforderungen für die Daten adressieren, die Ihre KI-Agenten benötigen.
Phase 3: Mit Single-Agent-Deployment validieren
Das ist der Ansatz, den wir im Crawl-Walk-Run-Framework aus Teil 1beschrieben haben. Das Ziel ist nicht nur, einen Workflow zu automatisieren. Es ist, zu validieren, dass Ihre Integrationsbasis funktioniert. Messen Sie, wo Issues auftreten. Iterieren Sie an der Infrastruktur, bevor Sie skalieren.
Zum Beispiel: Deployen Sie Single-Agent-Automatisierung für einen eingegrenzten UseCase wie Pre-Call-Screening oder Terminbestätigungen, etwas mit hohem Volumen und klaren Erfolgskriterien.
Phase 4: Für Orchestrierung vorbereiten
Bis Orchestrierungs-Fähigkeiten produktionsreif sind, sollte Ihre Infrastruktur bereit sein, sie zu nutzen. In dieser Phase müssen Sie gegebenenfalls:
- Multi-Agent-Handoffs ergänzen
- Audit-Trail-Fähigkeiten aufbauen, die Kontext beim Weiterreichen zwischen Agenten nachverfolgen
- A2A- und MCP-Kompatibilität testen, wenn Anbieter-Features ausgeliefert werden
Der Weg nach vorn
Die Protokolle standardisieren sich. Anbieterkompetenzen werden ausgeliefert. Die Frage ist, ob Ihre Infrastruktur bereit sein wird, sie zu nutzen. Mit Orchestrierungs-Fähigkeiten, die Anfang 2026 ausgeliefert werden, werden Organisationen mit solider Basis in der Lage sein zu handeln, während andere noch Integrationslücken schliessen.
Diese Arbeit beginnt jetzt – solange noch genug Zeit ist, es richtig zu machen.
Bucher + Suter hilft Contact Centern dabei, die Integrationsbasis aufzubauen, die KI-Agent-Deployments zum Funktionieren bringt. Wenn Sie evaluieren, wo Sie starten sollen: Lassen Sie uns sprechen.