Complete visibility has its advantages. When your AI can score 100% of your agent-customer interactions, instead of the much smaller percentage that manual QA catches, you’ve effectively eliminated blind spots and sampling bias.
But there’s another side to the story.
Today, 75% of contact center leaders are worried about AI’s impact on agent wellbeing. Ironic, isn’t it, since reducing agent stress is one of the top reasons for investing in call scoring solutions in the first place.
It turns out that maximizing a productivity measure like call scoring may turn out to be counterproductive. Often, what matters more—and is actually best for agents—is understanding what call scoring is for.
Problem 1: Measure Everything, Change Everything
Modern AI quality management systems can analyze every interaction in real time, including:
- Tracking sentiment shifts
- Script adherence
- Empathy indicators
- Response timing across voice, chat, and digital channels
That’s a lot of conversational data, and QA scoring is just one way to use it. For supervisors, the appeal is obvious: performance metrics across the entire team, with no conversation left unanalyzed.
However, a lot of actual agents see performance data as more for disciplinary reasons than skill development. One study found that two-thirds of workers in general see performance reviews as “a complete waste of time that doesn’t help them perform better.”
When agents perceive QA as surveillance, their behavior tends to shift. Even when they’re confident they’re doing the right thing for customers, there’s a background awareness that an algorithm is forming its own judgment.
That cognitive overhead has a name: vigilance tax.
That is, while agents manage customer interactions, they’re also managing their relationship with the scoring system. Perhaps this dynamic contributes to high stress levels and burnout so consistently reflected in the latest research.
It’s a feedback loop that works against itself: the more comprehensively you measure, the more you change what you’re measuring.
Problem 2: More Data, Same Bottleneck
Another problem: most organizations don’t or cannot effectively act on their scoring data. Even with complete AI-powered scoring. That’s because visibility isn’t the same as improvement.
A common scoring/correction workflow might look like this:
- QA surfaces a pattern
- The finding gets added to a coaching queue
- A supervisor schedules time when bandwidth allows
- Training materials get developed based on what was true weeks earlier.
By the time feedback reaches agents, the moment has usually passed. The system generates insights faster than the organization can absorb them.
This is the insight-to-action gap. Scaling from 2% to 100% coverage doesn’t solve it. In many cases, it makes the gap wider. More data without more coaching capacity just creates a bigger backlog of insights that never translate into agent development.
Dashboards love these environments, because they tend to flourish in them. Actual outcomes? Not so much. In our experience, the teams getting measurable results have connected QA to coaching workflows, turning insights into development conversations rather than compliance checkboxes.
From Monitoring to Enablement
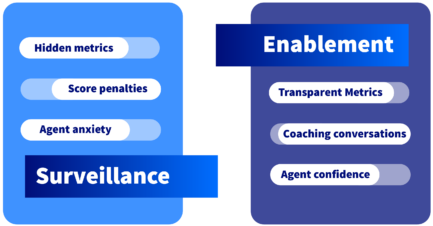
This undercurrent in AI quality management speaks to the requisite reframing already happening. Put simply: enablement, not surveillance.
Cisco’s recent announcement of Webex AI Quality Management, planned for Q1 2026, reflects this evolution. The platform is designed to evaluate both human agents and AI agents through the same lens. It applying consistent standards regardless of who (or what) handled the interaction.
Cisco’s positioning is telling: the company describes Webex AI QM as focused on what happens after the score—coaching, development, continuous improvement—rather than compliance alone. Their phrase is “beyond compliance metrics,” which signals where they see the market moving.
What Cisco is really saying is that QA systems succeed or fail based on how agents experience them.
Actual enablement depends on some core design principles:
Transparency about how scoring works. Hidden metrics erode trust faster than tough feedback. When agents understand what the algorithm measures and why, they’re more likely to engage with it as a development tool rather than resist it as a threat.
Training for confidence alongside compliance. The goal should be helping agents understand when to follow AI suggestions and when to override them. Professional judgment still matters, and agents need permission to use it.
Protecting space for professional judgment. Document agent overrides as examples of expertise, not failures. The experienced agent who deviates from the script to handle a sensitive situation shouldn’t see their score dip because they chose empathy over algorithm alignment.
Monitoring wellbeing with the same rigor as performance metrics. Some contact centers still don’t measure employee satisfaction or stress levels. You can’t manage what you don’t measure, and agent experience directly impacts customer experience.
What This Mean for Your QA Strategy
The race to auto-score every interaction is understandable. The technology exists. The vendors are pushing it. And there’s intuitive appeal in the idea that more data equals better decisions.
But implementation expertise matters as much as platform selection.
Before expanding AI quality management, here are a few questions worth asking:
- How will agents experience this system day-to-day? If the answer is “constant surveillance,” expect resistance.
- What’s the plan for connecting insights to coaching at scale? Dashboards without coaching workflows may just create a more sophisticated version of the same bottleneck.
- Are we measuring wellbeing alongside performance? Agent stress and turnover have direct costs. If your QA system is contributing to both, the ROI calculation changes.
- Does our culture support transparency about how scoring works? Trust is the foundation. Without it, even the best technology becomes a source of friction rather than improvement.
The organizations getting this right have made implementation thinking as much a priority as the technology itself. They’re asking “what can we measure?” But also “what should we do with what we learn?” And they’re building he systems to act on the answer.